

mnistによる手書き数字画像の予測を色々と試してきました。今回はブラウザ上で書いた画像に対して予測をしてみます。
前回
保存した画像に対する数値予測については、前回実施しました。以下のページに記載しています。

作成ソース
今回、Web上で画像予測をするにあたり、PHP,apacheを使いました。pythonでもWebアプリを作成できると思いますが、私が使い慣れているPHPにしています。
Dockerfile
今回は実行環境の構築のためにDockerfileを用意しました。
FROM php:7.2-apache
RUN apt-get update && apt-get -y install vim less
RUN apt-get update && apt-get -y install python3-dev python3-pip
RUN apt-get update && apt-get -y install curl
RUN mkdir -p /home/keras
RUN pip3 install -U virtualenv && virtualenv --system-site-packages -p python3 /home/keras/venv
RUN . /home/keras/venv/bin/activate && \
/home/keras/venv/bin/pip install --upgrade pip && \
/home/keras/venv/bin/pip install --upgrade tensorflow-cpu && \
/home/keras/venv/bin/pip install --upgrade keras && \
/home/keras/venv/bin/pip install --upgrade opencv-python && \
/home/keras/venv/bin/pip install --upgrade Pillow
RUN mkdir -p /home/keras/lib && \
mkdir -p /home/keras/images && \
chmod 757 /home/keras/images
COPY ./python /home/keras/lib
COPY ./php /var/www/html/必要なpythonのライブラリなどのインストールと後述のpythonファイル、phpファイルの配置を行っています。
python
作成したpythonのコードが以下です。
import sys
import numpy as np
from PIL import Image, ImageOps
from keras.models import load_model
# メソッド定義(指定したファイルを予測)
def predict_classes(im_file, model):
# 画像ファイル読み込み
im = Image.open(im_file)
# 画像ファイル変換
im = im.convert('L') # 白黒変換
im = im.resize((28, 28)) # サイズ調整
im = ImageOps.invert(im) # 値反転
# 画像データから検証データ作成
x = np.array(im) # NumPy配列に
x = x.reshape(1, 784) # 28*28 -> 784
x = x.astype('float32') # intからfloatに
x /= 255 # 0-1の範囲のfloatに
# 予測
predict_y = np.argmax(model.predict(x), axis=-1)
print('予測ラベル', predict_y)
# 実行
# 対象ファイル
args = sys.argv
im_file = args[1];
# 訓練済みモデル読み込み
model_file = '/home/keras/lib/my_model.h5'
model = load_model(model_file)
# 予測
predict_classes(im_file, model)
基本的には前回の画像ファイルを予測したコードと似た形になっていますが、予測する画像ファイルをptyhon実行時の引数で指定するように変更しています。
php
functions.php(メインロジック)
ブラウザからリクエストされた画像データを受け取り、ラベル(数値)予測を行うコードが以下です。
<?php
require_once 'consts.php';
function predict()
{
$imgBase64 = '';
if (isset($_POST['imgBase64'])) {
$imgBase64 = $_POST['imgBase64'];
}
if ($imgBase64 == '' || $imgBase64 == EMPTY_BASE64) {
return '';
}
$file_name = '/home/keras/images/' . date("Ymd_His", time()) . '.png';
$decode = base64_decode($imgBase64);
file_put_contents($file_name, $decode);
$python_bin = '/home/keras/venv/bin/python';
$python_module = '/home/keras/lib/main.py';
$command = $python_bin . ' ' . $python_module . ' ' . $file_name . ' 2>&1';
exec($command, $output);
$result = '';
$result .= '<div class="candiv"><img src="data:image/png;base64,' . $imgBase64 . '" /></div>';
foreach ($output as $value) {
$result .= $value . '<br>';
}
return $result;
}
?>
POST情報受け取り
以下の部分でPOSTされた画像データを受け取っています。画像データがリクエストされていない場合は処理を終了しています。
$imgBase64 = '';
if (isset($_POST['imgBase64'])) {
$imgBase64 = $_POST['imgBase64'];
}
if ($imgBase64 == '' || $imgBase64 == EMPTY_BASE64) {
return '';
}なお、画像エリアを変更せずに送信された場合(白紙のデータの場合)も処理を終了しています。EMPTY_BASE64は別途定義している定数で、白紙の場合の固定値です。
画像保存
以下の部分で、受け取った画像データを一旦ファイルに保存しています。
$file_name = '/home/keras/images/' . date("Ymd_His", time()) . '.png';
$decode = base64_decode($imgBase64);
file_put_contents($file_name, $decode);python実行
以下の部分で、pythonのコードを実行しています。実行結果はexecの第二引数($output)に格納されます。
$python_bin = '/home/keras/venv/bin/python';
$python_module = '/home/keras/lib/main.py';
$command = $python_bin . ' ' . $python_module . ' ' . $file_name . ' 2>&1';
exec($command, $output);今回、各種ライブラリはpythonの仮想環境(virtualenv)上にインストールしていますが、それらを使うためにpythonの実行ファイルは仮想環境のものをフルパスで指定しています。
予測結果表示
以下の部分で、表示用に予測結果を組み立てています。
$result = '';
$result .= '<div class="candiv"><img src="data:image/png;base64,' . $imgBase64 . '" /></div>';
foreach ($output as $value) {
$result .= $value . '<br>';
}
return $result;今思うとこれは表示側で組み立てても良かったかもしれないです。
index.php(表示部分)
表示部分は以下のようになっています。手書き画像のためのキャンバス(canvas)の表示をしています。また、予測を行った場合は、予測結果も表示しています。
<?php
require_once 'functions.php';
?>
<!DOCTYPE html>
<html lang="ja">
<head>
<META http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>手書き文字の数字予測</title>
<style type="text/css"></style>
<link rel="stylesheet" href="common.css">
<script type="text/javascript" src="common.js"></script>
</head>
<body onload="mam_draw_init();">
<h3>手書き文字の数字予測</h3>
<div class="candiv" id="candiv">
<canvas id="can" width="150px" height="150px"></canvas>
</div>
<br>
<input type="button" onClick="clearCan();" value="クリア" class="button" data-inline="true" />
<form id="fm" name="fm" method="post" action="/" style="display: inline;">
<input type="button" onClick="savePic();" value="予測" class="button" data-inline="true" />
<input type="hidden" name="imgBase64" id="imgBase64" value="" data-inline="true" />
</form>
<br>
<br>
<h3>予測結果</h3>
<?= predict();?>
</body>
</html>JavaScript
今回、html5のcanvasを用いてWeb上(ブラウザ上)で画像を描いています。その部分は参考サイトのものとほぼ同じなので、ここでは省略します。参考サイトのURLを貼っておくので、そちらを参照してもらえればと思います。
実行
作成したコードを実際に実行してみます。dockerコンテナの起動は本題とは離れるので、コンテナ起動後の画面表示から記載します。
初期表示
初期表示は以下のようになります。黒枠の中に線を描けるようになっています。
入力
黒枠の中で線を描くと以下のようになります。

この状態で「予測」ボタンを押下すると予測が始まります。
予測
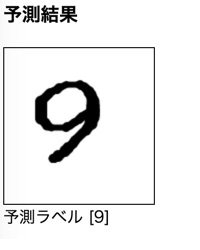
「予測」ボタンを押下し、しばらく待つと結果が表示されます。

上記のように入力した画像と予測ラベルが表示されるようにしています。
結果色々
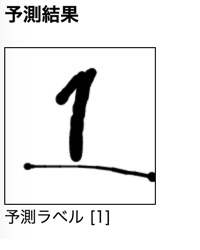
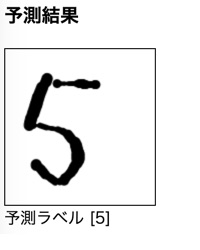
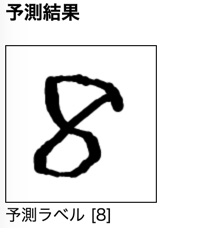
先ほどは予測がうまく行った結果を載せましたが、実際は結構シビアな感じでした。元々が手書き画像ということもあり、学習データと入力データのギャップが結構大きいのではないかと思います。学習データには存在する色の濃淡が入力データにはない(ほぼない?)点も影響していそうな気がします。
以下にうまくいった結果をのせておきます。






参考サイト
今回、canvasを使う部分は以下のサイトを参考にしました。
https://mam-mam.net/javascript/draw_js.html
ただし、keras,mnistによる予測を行うにあたって、線の太さなども予測結果に影響を与えるので、それらは多少変更しています。
作成物
今回の作成物は以下に置いてあります。
https://github.com/masaki-code/python/tree/master/public/mnist_predict_web
コメント