

G検定を合格し知識を得たので、今度は実際に動かして試してみたいと思います。サンプルとしてmnistを用いていきます。ちょっとした解説付きです。
言語など
- 言語:Python
- フレームワーク:TensorFlow、Keras
- サンプルデータセット:mnist
学習に用いるサンプルソース
以下のKerasのサンプルプログラムを用います。
https://github.com/keras-team/keras/blob/master/examples/mnist_mlp.py
なお、本書の作成時点(2020年5月初)のコミットは「4f2e65c on 23 Feb 2018」です。最新のコミットが異なっている場合は本書の記載とずれている可能性がありますので、注意してください。
解説
インポート文(8行目〜14行目)
コメント行や空白行を除くと最初に登場するのは以下のインポート文です。
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.optimizers import RMSprop上記は基本的にPythonの話になりますが、Kerasのモジュールを読み込んでいることが分かります。
mnist
「from keras.datasets import mnist」はmnistのモジュールのインポートです。Kerasで使えるデータセットについては以下に記載があります。
Sequential
「from keras.models import Sequential」はSequentialモデル(系列モデル)のモジュールのインポートです。Sequentialモデルについては以下に記載があります。
https://keras.io/ja/getting-started/sequential-model-guide/
Dense, Dropout
「from keras.layers import Dense, Dropout」はレイヤーのモジュールのインポートです。レイヤーはSequentialに追加します。ここでインポートしているレイヤーの詳細は以下に記載があります。
https://keras.io/ja/layers/core/
RMSprop
「from keras.optimizers import RMSprop」はオプティマイザ(最適化アルゴリズム)の中のRMSPropオプティマイザのモジュールのインポートです。オプティマイザについては以下に記載があります。
https://keras.io/ja/optimizers/
定数定義(16行目〜18行目)
インポート文の後には以下の定数定義が記載されています。
batch_size = 128
num_classes = 10
epochs = 20データのロード(21行目)
以下はmnistのデータをロードする箇所です。
(x_train, y_train), (x_test, y_test) = mnist.load_data()詳しくは「mnist」のインポートのところに記載したリンク先に説明がありますが、訓練用のデータと検証用のデータをロードしています。ダウンロードなので最初はそれなりに時間がかかりますが、ロードしたデータは所定の位置に保存されるので、2回目以降の実行の際はすぐに完了します。
データの変換(23行目〜28行目)
以下はロードしたデータの変換部分です。
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255用意されているデータから更に扱いやすいようにデータを変換しています。
reshape
最初のreshapeの部分は次元の変換です。この関数自体はPythonの関数なので説明はしませんが、NumPyで検索すると分かりやすい記事が見つかると思います。
ここでの変換は以下のようなイメージです。
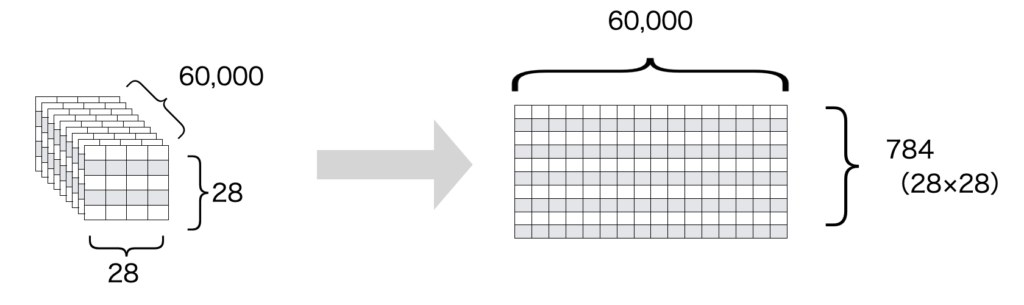
元々用意されているデータは画像(2次元)にデータ個数(1次元)をかけた3次元データですが、画像の部分を1次元のベクトルに次元を落としています。
astypeと/= 255
astypeと255で割っている部分はデータのサイズを整えています。元々は0から255までの整数値をとりますが、変換することで0から1までの小数になります。
データのログ出力(29行目〜30行目)
以下はここまでのロード、加工したデータの情報をログ出力しています。これは省略します。
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')クラスベクトルのクラス行列変換(33行目〜34行目)
以下は結果ラベルである0から9の数字をone-hot-encodingしています。
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)イメージ的には以下のような感じです。
0 -> (1, 0, 0, 0, 0, 0, 0, 0, 0, 0) 1 -> (0, 1, 0, 0, 0, 0, 0, 0, 0, 0) 2 -> (0, 0, 1, 0, 0, 0, 0, 0, 0, 0) … 7 -> (0, 0, 0, 0, 0, 0, 0, 1, 0, 0) 8 -> (0, 0, 0, 0, 0, 0, 0, 0, 1, 0) 9 -> (0, 0, 0, 0, 0, 0, 0, 0, 0, 1)
モデルの作成(36行目〜41行目)
以下はモデルの作成部分になります。
model = Sequential()
model.add(Dense(512, activation='relu', input_shape=(784,)))
model.add(Dropout(0.2))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(num_classes, activation='softmax'))Denseの最初の引数(512やnum_classes)は(そのレイヤーでの)出力の次元数です。
activationは活性化関数を指定しています。reluはReLU(ランプ関数)、softmaxはソフトマックス関数です。G検定でもありましたが、途中(隠れ層)はReLU、出力層付近はソフトマックス関数を使うと良い結果を得られるため、このような指定をしているのだと思います。
input_shapeは入力のデータ数を指定しています。前述の通り、元の28×28の画像データを784のベクトルに変換しているので、その数を指定しています。input_shapeは最初のレイヤー以外は前のレイヤーの出力の次元数で分かるので不要です。
Dropoutはドロップアウトです。過学習を防ぐために使われます。引数の数値は無効化する割合を指定しています。
モデルをイメージしてみると以下のような感じです。ドロップアウトは省略しています。
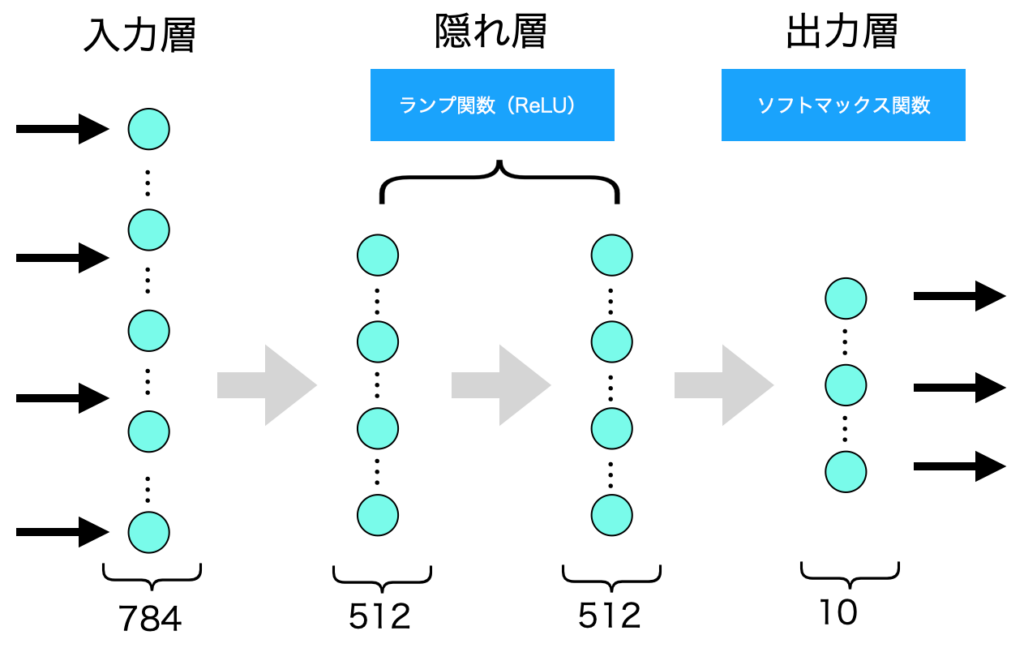
サマリ表示(43行目)
以下は作成したモデルのサマリの表示です。
model.summary()上記は以下のようになります。
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 512) 401920
_________________________________________________________________
dropout_1 (Dropout) (None, 512) 0
_________________________________________________________________
dense_2 (Dense) (None, 512) 262656
_________________________________________________________________
dropout_2 (Dropout) (None, 512) 0
_________________________________________________________________
dense_3 (Dense) (None, 10) 5130
=================================================================
Total params: 669,706
Trainable params: 669,706
Non-trainable params: 0
_________________________________________________________________上記にあるパラメータ数(Param)ですが、それぞれ以下のような計算になります。
- 401,920 = (784 +1) × 512
- 262,656 = (512 +1) × 512
- 5,130 = (512 +1) × 10
これは重みの数が入力と同じ数でそこにバイアスの分で1を足し、更に出力の次元数をかけたものになります。イメージ的には以下が出力次元数だけある感じになります。
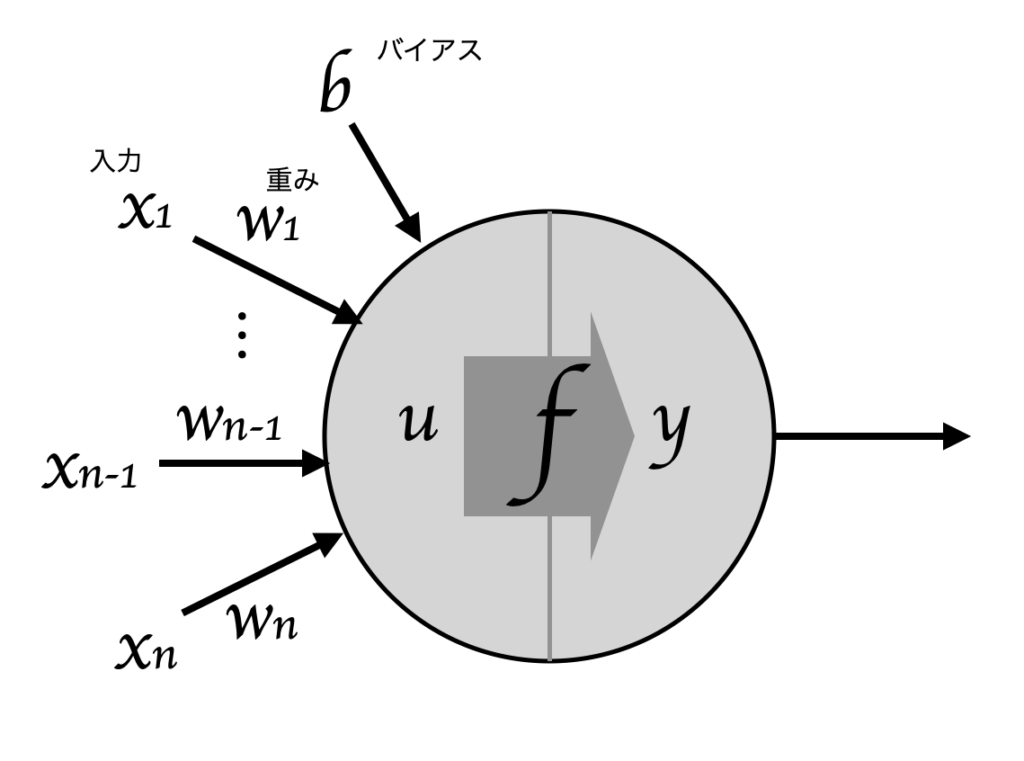
コンパイル(45行目〜47行目)
以下はモデルのコンパイルです。どのような学習処理を行なうかの設定しています。
model.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])lossは損失関数です。誤差の計算をどのような関数で実施するかを指定します。categorical_crossentropyはクロスエントロピーというもののようです。
optimizerは最適化アルゴリズムです。RMSpropはRMSPropオプティマイザというもののようです。
metricsは評価関数です。モデルの性能を測るために用いられるものです。accuracyが具体的に何かは公式サイトを見ても分かりませんでしたが、調べたところデフォルトではcategorical_accuracyになるという記事を見つけました。
訓練(49行目〜53行目)
以下は実際の学習(訓練)の部分です。
history = model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))最初の2つの引数は訓練データです。最初にロードして加工したものになります。
batch_sizeは公式のドキュメントでは勾配更新毎のサンプル数と記載されていました。単純にバッチ実行の際のサイズと思えば良いと思います。
epochsはエポックです。エポックは訓練データを何度学習に用いたか(反復回数)です。
verboseは進行状況の表示モードです。あまり訓練自体とはあまり関係のない部分かと思います。0が表示なし、1がプログレスバー、2が各試行毎に一行の出力となっています。
validation_dataは訓練の際の評価に用いるテストデータです。これも最初にロードして加工したものです。
損失値の計算と表示(54行目〜56行目)
以下はモデルの損失値と評価値を計算しています。
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])evaluateは計算部分です。verboseが0なのでevaluate自体は表示がありません。
evaluateでの計算後に計算した値をprintで表示しています。
実行結果
最後に全体を通した実行結果を載せておきます。
$ python mnist_mlp.py
Using TensorFlow backend.
60000 train samples
10000 test samples
2020-05-31 21:15:31.448012: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
2020-05-31 21:15:31.509887: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x7f894c28d560 initialized for platform Host (this does not guarantee that XLA will be used). Devices:
2020-05-31 21:15:31.509935: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 512) 401920
_________________________________________________________________
dropout_1 (Dropout) (None, 512) 0
_________________________________________________________________
dense_2 (Dense) (None, 512) 262656
_________________________________________________________________
dropout_2 (Dropout) (None, 512) 0
_________________________________________________________________
dense_3 (Dense) (None, 10) 5130
=================================================================
Total params: 669,706
Trainable params: 669,706
Non-trainable params: 0
_________________________________________________________________
Train on 60000 samples, validate on 10000 samples
Epoch 1/20
60000/60000 [==============================] - 9s 153us/step - loss: 0.2456 - accuracy: 0.9231 - val_loss: 0.1057 - val_accuracy: 0.9655
Epoch 2/20
60000/60000 [==============================] - 6s 108us/step - loss: 0.1011 - accuracy: 0.9693 - val_loss: 0.0873 - val_accuracy: 0.9719
Epoch 3/20
60000/60000 [==============================] - 10s 163us/step - loss: 0.0744 - accuracy: 0.9774 - val_loss: 0.0826 - val_accuracy: 0.9771
Epoch 4/20
60000/60000 [==============================] - 7s 110us/step - loss: 0.0605 - accuracy: 0.9821 - val_loss: 0.0717 - val_accuracy: 0.9822
Epoch 5/20
60000/60000 [==============================] - 6s 99us/step - loss: 0.0505 - accuracy: 0.9839 - val_loss: 0.0806 - val_accuracy: 0.9794
Epoch 6/20
60000/60000 [==============================] - 6s 103us/step - loss: 0.0424 - accuracy: 0.9874 - val_loss: 0.0771 - val_accuracy: 0.9821
Epoch 7/20
60000/60000 [==============================] - 6s 108us/step - loss: 0.0373 - accuracy: 0.9889 - val_loss: 0.0858 - val_accuracy: 0.9810
Epoch 8/20
60000/60000 [==============================] - 6s 107us/step - loss: 0.0331 - accuracy: 0.9903 - val_loss: 0.0945 - val_accuracy: 0.9804
Epoch 9/20
60000/60000 [==============================] - 7s 108us/step - loss: 0.0318 - accuracy: 0.9909 - val_loss: 0.0861 - val_accuracy: 0.9826
Epoch 10/20
60000/60000 [==============================] - 7s 110us/step - loss: 0.0277 - accuracy: 0.9920 - val_loss: 0.0928 - val_accuracy: 0.9814
Epoch 11/20
60000/60000 [==============================] - 6s 107us/step - loss: 0.0279 - accuracy: 0.9923 - val_loss: 0.1003 - val_accuracy: 0.9807
Epoch 12/20
60000/60000 [==============================] - 7s 112us/step - loss: 0.0247 - accuracy: 0.9927 - val_loss: 0.0938 - val_accuracy: 0.9825
Epoch 13/20
60000/60000 [==============================] - 7s 116us/step - loss: 0.0230 - accuracy: 0.9937 - val_loss: 0.0986 - val_accuracy: 0.9829
Epoch 14/20
60000/60000 [==============================] - 7s 121us/step - loss: 0.0227 - accuracy: 0.9937 - val_loss: 0.1012 - val_accuracy: 0.9830
Epoch 15/20
60000/60000 [==============================] - 7s 125us/step - loss: 0.0212 - accuracy: 0.9937 - val_loss: 0.1163 - val_accuracy: 0.9842
Epoch 16/20
60000/60000 [==============================] - 8s 133us/step - loss: 0.0215 - accuracy: 0.9942 - val_loss: 0.1196 - val_accuracy: 0.9828
Epoch 17/20
60000/60000 [==============================] - 8s 133us/step - loss: 0.0190 - accuracy: 0.9950 - val_loss: 0.1118 - val_accuracy: 0.9837
Epoch 18/20
60000/60000 [==============================] - 9s 142us/step - loss: 0.0185 - accuracy: 0.9949 - val_loss: 0.1301 - val_accuracy: 0.9827
Epoch 19/20
60000/60000 [==============================] - 8s 135us/step - loss: 0.0173 - accuracy: 0.9950 - val_loss: 0.1401 - val_accuracy: 0.9821
Epoch 20/20
60000/60000 [==============================] - 8s 138us/step - loss: 0.0174 - accuracy: 0.9956 - val_loss: 0.1334 - val_accuracy: 0.9825
Test loss: 0.1333503323278276
Test accuracy: 0.9825000166893005
$訓練後の判定について
以上で訓練(学習)ができましたが、実際に訓練後のモデルで判定してみたいと考えると思います。
その際は以下のようにpredictで評価できます。詳細は省きますが以下の「x」は自作のテスト用のデータでラベル7のデータ(7の画像のデータ)です。
ret = model.predict(x, batch_size=None, verbose=0, steps=None)
print(ret[0])上記を実行すると以下のような結果が得られます。
[2.82711148e-33 4.49353410e-23 1.04254898e-21 1.08021035e-23
6.95831989e-29 2.19240989e-27 0.00000000e+00 1.00000000e+00
1.77899486e-25 6.43885184e-23]少し分かりづらいですが、7に該当する部分の値は1で、それ以外の部分は0か非常に小さい数字(比較的大きいものでもe-21)になっています。
変換処理は省きますが非常に小さい数値は0に丸めてみると以下のようになります。
[0, 0, 0, 0, 0, 0, 0, 1.0, 0, 0]8番目(0のラベルから始まるので7のラベルの部分)が1であり、他が0であることが分かります。
追記(2020/09/01)
その後、画像ファイルを読み込み数字ラベルを予測するということをしてみました。以下にまとめています。

コメント